





Advertisement

Advertisement
How do you like the idea of NOT saying " Oh I forgot, let me get back to you. "
Advertisement
INVBAT.COM - AI revolutionizing education and how to remember using augmented intelligence.
Try typing or saying I need the quadratic formula
Try typing or saying get me the quadratic formula
Try typing or saying show me the quadratic formula
ASK WHAT YOU NEED. TRY I NEED QUADRATIC EQUATION
AI Natural Language Query makes one click search now possible
Enter your access code above or ask what you need
INVBAT.COM - A.I. + CHATBOT voice search for formula , calculator, reviewer, work procedure and frequently asked questions (FAQ). It is useful immediately and on demand using your smartphone, notebook, tablet, laptop or desktop computer. Helping you to learn faster and 98% never forget.
INVBAT.COM - AI + CHATBOT is a personalized natural language search and information retrieval augmented intelligence service provider. We deliver immediate usefulness at affordable cost to our subscriber such as students, teachers, parents, and employees to help them remember what they stored in the cloud in one or fewer click using their smartphone, tablet, laptop, desktop computer, and smart tv.

Advertising rate $375 per year
Additional bonus if your school , community college, and university advertise, all your students and teachers will get free personal memory assistant chatbot for one month.
Advertise on this webpage. Use PayPal
After payment e-mail admin@invbat.com your advertising website link or your You Tube link and we will insert them on this webpage.

# comment: How do you compare different machine learning algorithm for accuracy in making prediction?
# comment: When Comparing, validating and choosing parameters and models use GridSearchCV (CV means Cross Validation)
# Author: Raghav RV <rvraghav93@gmail.com>
# modified for personal use by : Sam Ortega 6/13/2020 <samxcl@yahoo.com>
# License: BSD
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_hastie_10_2
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
print(__doc__)
print('')
# comment : Running GridSearchCV using multiple evaluation metrics
X, y = make_hastie_10_2(n_samples=8000, random_state=42)
# The scorers can be either be one of the predefined metric strings or a scorer
# callable, like the one returned by make_scorer
scoring = {'AUC': 'roc_auc', 'Accuracy': make_scorer(accuracy_score)}
# Setting refit='AUC', refits an estimator on the whole dataset with the
# parameter setting that has the best cross-validated AUC score.
# That estimator is made available at ``gs.best_estimator_`` along with
# parameters like ``gs.best_score_``, ``gs.best_params_`` and
# ``gs.best_index_``
gs = GridSearchCV(DecisionTreeClassifier(random_state=42),
param_grid={'min_samples_split': range(2, 403, 10)},
scoring=scoring, refit='AUC', return_train_score=True)
gs.fit(X, y)
results = gs.cv_results_
# comment : Plotting the result
plt.figure(figsize=(13,13))
plt.title("GridSearchCV evaluating using multiple scorers simultaneously",
fontsize=16)
plt.xlabel("minimum_samples_split")
plt.ylabel("Score")
ax = plt.gca()
ax.set_xlim(0, 402)
ax.set_ylim(0.73, 1)
# Get the regular numpy array from the MaskedArray
X_axis = np.array(results['param_min_samples_split'].data, dtype=float)
# comment : I remember color 'g' for green, color 'k' for black , color 'r' for red
for scorer, color in zip(sorted(scoring), ['r', 'k']):
# comment : green color style used in 'train' and the line style is '--'
# comment : black color style used in 'test' and the line style is '-'
for sample, style in (('train', '--'), ('test', '-')):
sample_score_mean = results['mean_%s_%s' % (sample, scorer)]
sample_score_std = results['std_%s_%s' % (sample, scorer)]
ax.fill_between(X_axis, sample_score_mean - sample_score_std,
sample_score_mean + sample_score_std,
alpha=0.1 if sample == 'test' else 0, color=color)
ax.plot(X_axis, sample_score_mean, style, color=color,
alpha=1 if sample == 'test' else 0.7,
label="%s (%s)" % (scorer, sample))
best_index = np.nonzero(results['rank_test_%s' % scorer] == 1)[0][0]
best_score = results['mean_test_%s' % scorer][best_index]
# Plot a dotted vertical line at the best score for that scorer marked by x
ax.plot([X_axis[best_index], ] * 2, [0, best_score],
linestyle='-.', color=color, marker='x', markeredgewidth=3, ms=8)
# Annotate the best score for that scorer
ax.annotate("%0.2f" % best_score,
(X_axis[best_index], best_score + 0.005))
plt.legend(loc="best")
plt.grid(False)
plt.show()
# comment # Do shift + enter
# comment # wait for 28 seconds to see the output
# comment AUC ? means Area Under the Curve

# comment : visualizing the probability calibration
print(__doc__)
print('')
# Author: Jan Hendrik Metzen <jhm@informatik.uni-bremen.de>
# modified for personal use by : Sam Ortega 6/13/2020 <samxcl@yahoo.com>
# License: BSD Style.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.calibration import CalibratedClassifierCV
from sklearn.metrics import log_loss
np.random.seed(0)
# Generate data
X, y = make_blobs(n_samples=1000, random_state=42, cluster_std=5.0)
X_train, y_train = X[:600], y[:600]
X_valid, y_valid = X[600:800], y[600:800]
X_train_valid, y_train_valid = X[:800], y[:800]
X_test, y_test = X[800:], y[800:]
# Train uncalibrated random forest classifier on whole train and validation
# data and evaluate on test data
clf = RandomForestClassifier(n_estimators=25)
clf.fit(X_train_valid, y_train_valid)
clf_probs = clf.predict_proba(X_test)
score = log_loss(y_test, clf_probs)
# Train random forest classifier, calibrate on validation data and evaluate
# on test data
clf = RandomForestClassifier(n_estimators=25)
clf.fit(X_train, y_train)
clf_probs = clf.predict_proba(X_test)
sig_clf = CalibratedClassifierCV(clf, method="sigmoid", cv="prefit")
sig_clf.fit(X_valid, y_valid)
sig_clf_probs = sig_clf.predict_proba(X_test)
sig_score = log_loss(y_test, sig_clf_probs)
# Plot changes in predicted probabilities via arrows
plt.figure(figsize=(12,6))
colors = ["r", "g", "b"]
for i in range(clf_probs.shape[0]):
plt.arrow(clf_probs[i, 0], clf_probs[i, 1],
sig_clf_probs[i, 0] - clf_probs[i, 0],
sig_clf_probs[i, 1] - clf_probs[i, 1],
color=colors[y_test[i]], head_width=1e-2)
# Plot perfect predictions
plt.plot([1.0], [0.0], 'ro', ms=20, label="Class 1")
plt.plot([0.0], [1.0], 'go', ms=20, label="Class 2")
plt.plot([0.0], [0.0], 'bo', ms=20, label="Class 3")
# Plot boundaries of unit simplex
plt.plot([0.0, 1.0, 0.0, 0.0], [0.0, 0.0, 1.0, 0.0], 'k', label="Simplex")
# Annotate points on the simplex
plt.annotate(r'($\frac{1}{3}$, $\frac{1}{3}$, $\frac{1}{3}$)',
xy=(1.0/3, 1.0/3), xytext=(1.0/3, .23), xycoords='data',
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='center', verticalalignment='center')
plt.plot([1.0/3], [1.0/3], 'ko', ms=5)
plt.annotate(r'($\frac{1}{2}$, $0$, $\frac{1}{2}$)',
xy=(.5, .0), xytext=(.5, .1), xycoords='data',
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($0$, $\frac{1}{2}$, $\frac{1}{2}$)',
xy=(.0, .5), xytext=(.1, .5), xycoords='data',
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($\frac{1}{2}$, $\frac{1}{2}$, $0$)',
xy=(.5, .5), xytext=(.6, .6), xycoords='data',
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($0$, $0$, $1$)',
xy=(0, 0), xytext=(.1, .1), xycoords='data',
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($1$, $0$, $0$)',
xy=(1, 0), xytext=(1, .1), xycoords='data',
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($0$, $1$, $0$)',
xy=(0, 1), xytext=(.1, 1), xycoords='data',
arrowprops=dict(facecolor='black', shrink=0.05),
horizontalalignment='center', verticalalignment='center')
# Add grid
plt.grid(False)
for x in [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]:
plt.plot([0, x], [x, 0], 'k', alpha=0.2)
plt.plot([0, 0 + (1-x)/2], [x, x + (1-x)/2], 'k', alpha=0.2)
plt.plot([x, x + (1-x)/2], [0, 0 + (1-x)/2], 'k', alpha=0.2)
plt.title("Change of predicted probabilities after sigmoid calibration")
plt.xlabel("Probability class 1")
plt.ylabel("Probability class 2")
plt.xlim(-0.05, 1.05)
plt.ylim(-0.05, 1.05)
plt.legend(loc="best")
print("Log-loss of")
print(" * uncalibrated classifier trained on 800 datapoints: %.3f "
% score)
print(" * classifier trained on 600 datapoints and calibrated on "
"200 datapoint: %.3f" % sig_score)
# Illustrate calibrator
plt.figure(figsize=(12,6))
# generate grid over 2-simplex
p1d = np.linspace(0, 1, 20)
p0, p1 = np.meshgrid(p1d, p1d)
p2 = 1 - p0 - p1
p = np.c_[p0.ravel(), p1.ravel(), p2.ravel()]
p = p[p[:, 2] >= 0]
calibrated_classifier = sig_clf.calibrated_classifiers_[0]
prediction = np.vstack([calibrator.predict(this_p)
for calibrator, this_p in
zip(calibrated_classifier.calibrators_, p.T)]).T
prediction /= prediction.sum(axis=1)[:, None]
# Plot modifications of calibrator
for i in range(prediction.shape[0]):
plt.arrow(p[i, 0], p[i, 1],
prediction[i, 0] - p[i, 0], prediction[i, 1] - p[i, 1],
head_width=1e-2, color=colors[np.argmax(p[i])])
# Plot boundaries of unit simplex
plt.plot([0.0, 1.0, 0.0, 0.0], [0.0, 0.0, 1.0, 0.0], 'k', label="Simplex")
plt.grid(False)
for x in [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]:
plt.plot([0, x], [x, 0], 'k', alpha=0.2)
plt.plot([0, 0 + (1-x)/2], [x, x + (1-x)/2], 'k', alpha=0.2)
plt.plot([x, x + (1-x)/2], [0, 0 + (1-x)/2], 'k', alpha=0.2)
plt.title("Illustration of sigmoid calibrator")
plt.xlabel("Probability class 1")
plt.ylabel("Probability class 2")
plt.xlim(-0.05, 1.05)
plt.ylim(-0.05, 1.05)
plt.show()
# comment # Do shift + enter
# comment: wait to see the output


# comment :
# Author : source: Sample from scikit-learn.org
# modified for personal use by : Sam Ortega 6/13/2020 <samxcl@yahoo.com>
# License: BSD Style.
print(__doc__)
print('')
import numpy as np
import matplotlib.pyplot as plt
from sklearn.covariance import EmpiricalCovariance, MinCovDet
n_samples = 125
n_outliers = 25
n_features = 2
# generate data
gen_cov = np.eye(n_features)
gen_cov[0, 0] = 2.
X = np.dot(np.random.randn(n_samples, n_features), gen_cov)
# add some outliers
outliers_cov = np.eye(n_features)
outliers_cov[np.arange(1, n_features), np.arange(1, n_features)] = 7.
X[-n_outliers:] = np.dot(np.random.randn(n_outliers, n_features), outliers_cov)
# fit a Minimum Covariance Determinant (MCD) robust estimator to data
robust_cov = MinCovDet().fit(X)
# compare estimators learnt from the full data set with true parameters
emp_cov = EmpiricalCovariance().fit(X)
# #############################################################################
# Display results
fig = plt.figure(figsize=(12,8))
plt.subplots_adjust(hspace=-.1, wspace=.4, top=.95, bottom=.05)
# Show data set
subfig1 = plt.subplot(3, 1, 1)
inlier_plot = subfig1.scatter(X[:, 0], X[:, 1],
color='black', label='inliers')
outlier_plot = subfig1.scatter(X[:, 0][-n_outliers:], X[:, 1][-n_outliers:],
color='red', label='outliers')
subfig1.set_xlim(subfig1.get_xlim()[0], 11.)
subfig1.set_title("Mahalanobis distances of a contaminated data set:")
# Show contours of the distance functions
xx, yy = np.meshgrid(np.linspace(plt.xlim()[0], plt.xlim()[1], 100),
np.linspace(plt.ylim()[0], plt.ylim()[1], 100))
zz = np.c_[xx.ravel(), yy.ravel()]
mahal_emp_cov = emp_cov.mahalanobis(zz)
mahal_emp_cov = mahal_emp_cov.reshape(xx.shape)
emp_cov_contour = subfig1.contour(xx, yy, np.sqrt(mahal_emp_cov),
cmap=plt.cm.PuBu_r,
linestyles='dashed')
mahal_robust_cov = robust_cov.mahalanobis(zz)
mahal_robust_cov = mahal_robust_cov.reshape(xx.shape)
robust_contour = subfig1.contour(xx, yy, np.sqrt(mahal_robust_cov),
cmap=plt.cm.YlOrBr_r, linestyles='dotted')
subfig1.legend([emp_cov_contour.collections[1], robust_contour.collections[1],
inlier_plot, outlier_plot],
['MLE dist', 'robust dist', 'inliers', 'outliers'],
loc="upper right", borderaxespad=0)
plt.xticks(())
plt.yticks(())
# Plot the scores for each point
emp_mahal = emp_cov.mahalanobis(X - np.mean(X, 0)) ** (0.33)
subfig2 = plt.subplot(2, 2, 3)
subfig2.boxplot([emp_mahal[:-n_outliers], emp_mahal[-n_outliers:]], widths=.25)
subfig2.plot(np.full(n_samples - n_outliers, 1.26),
emp_mahal[:-n_outliers], '+k', markeredgewidth=1)
subfig2.plot(np.full(n_outliers, 2.26),
emp_mahal[-n_outliers:], '+k', markeredgewidth=1)
subfig2.axes.set_xticklabels(('inliers', 'outliers'), size=15)
subfig2.set_ylabel(r"$\sqrt[3]{\rm{(Mahal. dist.)}}$", size=16)
subfig2.set_title("1. from non-robust estimates\n(Maximum Likelihood)")
plt.yticks(())
robust_mahal = robust_cov.mahalanobis(X - robust_cov.location_) ** (0.33)
subfig3 = plt.subplot(2, 2, 4)
subfig3.boxplot([robust_mahal[:-n_outliers], robust_mahal[-n_outliers:]],
widths=.25)
subfig3.plot(np.full(n_samples - n_outliers, 1.26),
robust_mahal[:-n_outliers], '+k', markeredgewidth=1)
subfig3.plot(np.full(n_outliers, 2.26),
robust_mahal[-n_outliers:], '+k', markeredgewidth=1)
subfig3.axes.set_xticklabels(('inliers', 'outliers'), size=15)
subfig3.set_ylabel(r"$\sqrt[3]{\rm{(Mahal. dist.)}}$", size=16)
subfig3.set_title("2. from robust estimates\n(Minimum Covariance Determinant)")
plt.yticks(())
plt.show()
# comment # Do shift + enter
# comment :

# comment : Using a robust estimator of covariance to guarantee that the estimation is resistant
# to “erroneous” observations in the data set.
# Author : source: Sample from scikit-learn.org
# modified for personal use by : Sam Ortega 6/13/2020 <samxcl@yahoo.com>
# License: BSD Style.
print(__doc__)
print('')
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn.covariance import EmpiricalCovariance, MinCovDet
# example settings
n_samples = 80
n_features = 5
repeat = 10
range_n_outliers = np.concatenate(
(np.linspace(0, n_samples / 8, 5),
np.linspace(n_samples / 8, n_samples / 2, 5)[1:-1])).astype(np.int)
# definition of arrays to store results
err_loc_mcd = np.zeros((range_n_outliers.size, repeat))
err_cov_mcd = np.zeros((range_n_outliers.size, repeat))
err_loc_emp_full = np.zeros((range_n_outliers.size, repeat))
err_cov_emp_full = np.zeros((range_n_outliers.size, repeat))
err_loc_emp_pure = np.zeros((range_n_outliers.size, repeat))
err_cov_emp_pure = np.zeros((range_n_outliers.size, repeat))
# computation
for i, n_outliers in enumerate(range_n_outliers):
for j in range(repeat):
rng = np.random.RandomState(i * j)
# generate data
X = rng.randn(n_samples, n_features)
# add some outliers
outliers_index = rng.permutation(n_samples)[:n_outliers]
outliers_offset = 10. * \
(np.random.randint(2, size=(n_outliers, n_features)) - 0.5)
X[outliers_index] += outliers_offset
inliers_mask = np.ones(n_samples).astype(bool)
inliers_mask[outliers_index] = False
# fit a Minimum Covariance Determinant (MCD) robust estimator to data
mcd = MinCovDet().fit(X)
# compare raw robust estimates with the true location and covariance
err_loc_mcd[i, j] = np.sum(mcd.location_ ** 2)
err_cov_mcd[i, j] = mcd.error_norm(np.eye(n_features))
# compare estimators learned from the full data set with true
# parameters
err_loc_emp_full[i, j] = np.sum(X.mean(0) ** 2)
err_cov_emp_full[i, j] = EmpiricalCovariance().fit(X).error_norm(
np.eye(n_features))
# compare with an empirical covariance learned from a pure data set
# (i.e. "perfect" mcd)
pure_X = X[inliers_mask]
pure_location = pure_X.mean(0)
pure_emp_cov = EmpiricalCovariance().fit(pure_X)
err_loc_emp_pure[i, j] = np.sum(pure_location ** 2)
err_cov_emp_pure[i, j] = pure_emp_cov.error_norm(np.eye(n_features))
# Display results
font_prop = matplotlib.font_manager.FontProperties(size=11)
plt.figure(figsize=(12,10))
plt.subplot(2, 1, 1)
lw = 2
plt.errorbar(range_n_outliers, err_loc_mcd.mean(1),
yerr=err_loc_mcd.std(1) / np.sqrt(repeat),
label="Robust location", lw=lw, color='m')
plt.errorbar(range_n_outliers, err_loc_emp_full.mean(1),
yerr=err_loc_emp_full.std(1) / np.sqrt(repeat),
label="Full data set mean", lw=lw, color='green')
plt.errorbar(range_n_outliers, err_loc_emp_pure.mean(1),
yerr=err_loc_emp_pure.std(1) / np.sqrt(repeat),
label="Pure data set mean", lw=lw, color='black')
plt.title("Influence of outliers on the location estimation", size=14)
plt.ylabel(r"Error ($||\mu - \hat{\mu}||_2^2$)", size=12)
plt.legend(loc="upper left", prop=font_prop)
plt.subplot(2, 1, 2)
x_size = range_n_outliers.size
plt.errorbar(range_n_outliers, err_cov_mcd.mean(1),
yerr=err_cov_mcd.std(1),
label="Robust covariance (mcd)", color='m')
plt.errorbar(range_n_outliers[:(x_size // 5 + 1)],
err_cov_emp_full.mean(1)[:(x_size // 5 + 1)],
yerr=err_cov_emp_full.std(1)[:(x_size // 5 + 1)],
label="Full data set empirical covariance", color='green')
plt.plot(range_n_outliers[(x_size // 5):(x_size // 2 - 1)],
err_cov_emp_full.mean(1)[(x_size // 5):(x_size // 2 - 1)],
color='green', ls='--')
plt.errorbar(range_n_outliers, err_cov_emp_pure.mean(1),
yerr=err_cov_emp_pure.std(1),
label="Pure data set empirical covariance", color='black')
plt.title("Influence of outliers on the covariance estimation", size=14)
plt.xlabel("Amount of contamination (%)")
plt.ylabel("RMSE")
plt.legend(loc="upper center", prop=font_prop)
plt.show()
# comment # Do shift + enter
# wait to see the output
# Minimum Covariance Determinant estimator (MCD)

# comment : How to plot in 3D the three principal component using PCA
# modified for personal use by : Sam Ortega 6/13/2020 <samxcl@yahoo.com>
# Code source: Gaël Varoquaux
# Modified for documentation by Jaques Grobler
# License: BSD 3 clause
print(__doc__)
print('')
import seaborn as sns
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import datasets
from sklearn.decomposition import PCA
# import some data to play with
iris = datasets.load_iris()
X = iris.data[:, :2] # we only take the first two features or fieldname column
y = iris.target
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
plt.figure(1, figsize=(8, 6))
plt.clf()
# Plot the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1,
edgecolor='k')
plt.xlabel('Sepal length, x-axis', size=12)
plt.ylabel('Sepal width, y-axis', size = 12)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
# To getter a better understanding of interaction of the dimensions
# plot the first three PCA dimensions
fig = plt.figure(2, figsize=(9, 7))
ax = Axes3D(fig, elev=-150, azim=110)
X_reduced = PCA(n_components=3).fit_transform(iris.data)
ax.scatter(X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2], c=y,
cmap=plt.cm.Set1, edgecolor='k', s=40)
ax.set_title("First three PCA directions")
ax.set_xlabel("1st eigenvector ")
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel("2nd eigenvector ")
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel("3rd eigenvector ")
ax.w_zaxis.set_ticklabels([])
plt.show()
# comment # Do shift + enter
# comment : wait to use the output


# comment show me the first 20 records of iris data set
# iris = pd.read_excel('/Users/invbat/projects/mpg.xlsx')
iris = pd.read_excel('/Users/invbat/projects/iris.xlsx')
iris.head(20)
# comment # Do shift + enter
# comment : wait to see the output
# comment : Get me the answer, how many total rows of record used in iris table? using .info() function
# the answer is 150 records or observation.
iris.info()
# comment # Do shift + enter
# comment : I want to see the pairwise analysis for PCA
sns.pairplot(iris);
# comment # Do shift + enter
# comment: wait to see the ouput


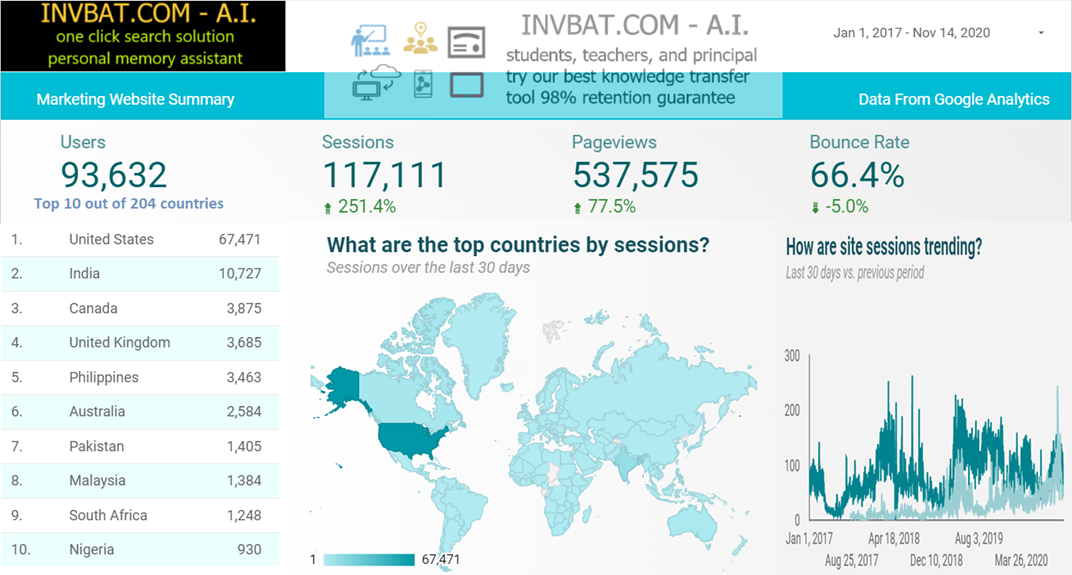
INVBAT.COM - A.I. is a disruptive innovation in computing and web search technology. For example scientific calculator help us speed up calculation but we still need to remember accurately the formula and the correct sequence of data entry. Here comes the disruptive innovation from INVBAT.COM-A.I. , today the problem of remembering formula and the correct sequence of data entry is now solved by combining formula and calculation and make it on demand using smartphone, tablet, notebook, Chromebook, laptop, desktop, school smartboard and company big screen tv in conference room with internet connection.
For web search , INVBAT.COM-A.I, is demonstrating that you can type text or use voice to text A.I. to search the web and get direct answer in one or two clicks. You don't need to waste your time looking from million of search results.